Introduction
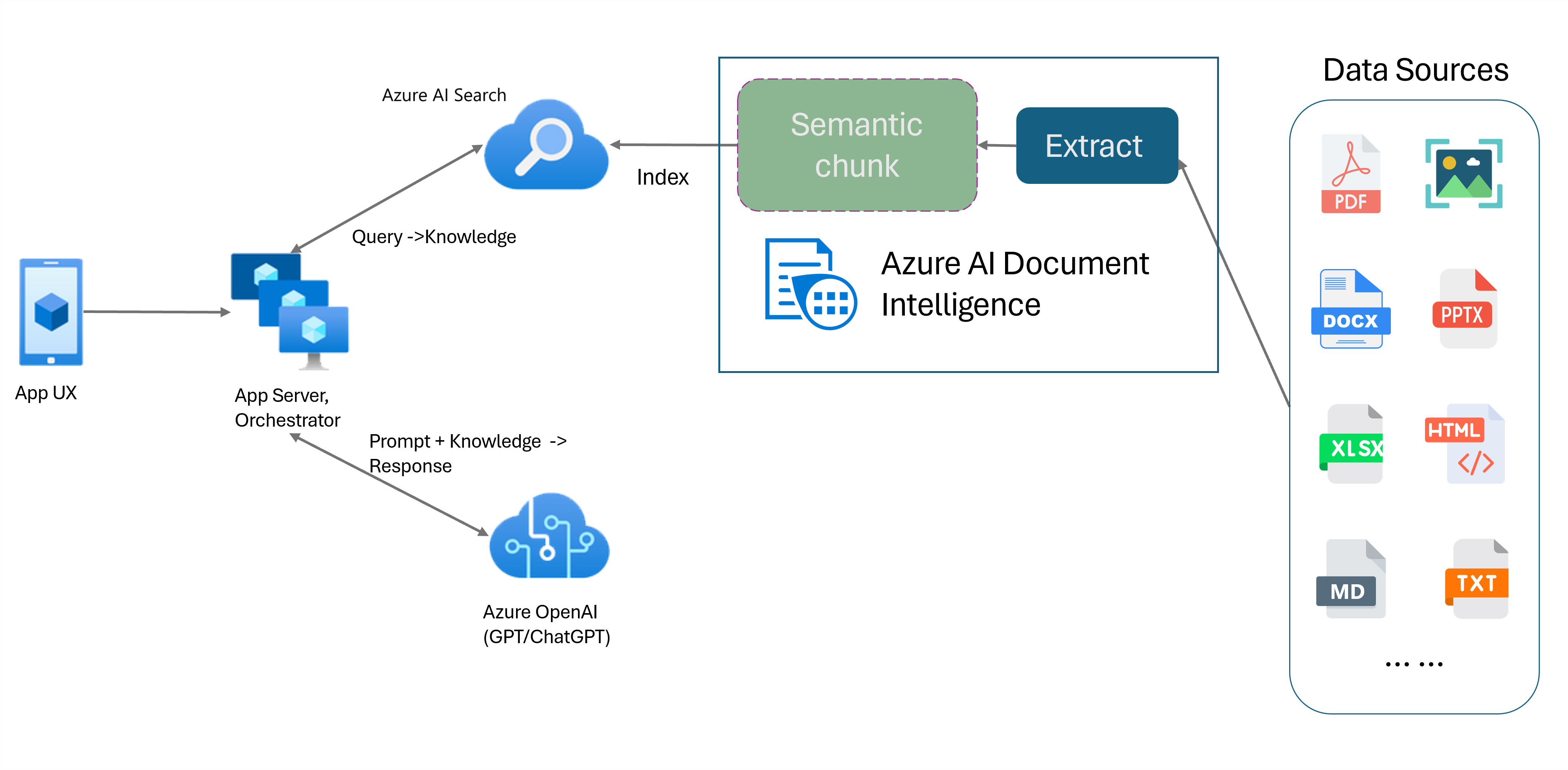
Retrieval-Augmented Generation (RAG) is a design pattern that combines a pretrained Large Language Model (LLM) like ChatGPT with an external data retrieval system to generate an enhanced response incorporating new data outside of the original training data. Adding an information retrieval system to your applications enables you to chat with your documents, generate captivating content, and access the power of Azure OpenAI models for your data. You also have more control over the data used by the LLM as it formulates a response.
The Document Intelligence Layout model is an advanced machine-learning based document analysis API. The Layout model offers a comprehensive solution for advanced content extraction and document structure analysis capabilities. With the Layout model, you can easily extract text and structural elements to divide large bodies of text into smaller, meaningful chunks based on semantic content rather than arbitrary splits. The extracted information can be conveniently outputted to Markdown format, enabling you to define your semantic chunking strategy based on provided building blocks.
Semantic chunking
Long sentences are challenging for natural language processing (NLP) applications. Especially when they’re composed of multiple clauses, complex noun or verb phrases, relative clauses, and parenthetical groupings. Just like the human beholder, an NLP system also needs to successfully keep track of all the presented dependencies. The goal of semantic chunking is to find semantically coherent fragments of a sentence representation. These fragments can then be processed independently and recombined as semantic representations without loss of information, interpretation, or semantic relevance. The inherent meaning of the text is used as a guide for the chunking process.
Text data chunking strategies play a key role in optimizing the RAG response and performance. Fixed-sized and semantic are two distinct chunking methods:
- Fixed-sized chunking. Most chunking strategies used in RAG today are based on fix-sized text segments known as chunks. Fixed-sized chunking is quick, easy, and effective with text that doesn’t have a strong semantic structure such as logs and data. However it isn’t recommended for text that requires semantic understanding and precise context. The fixed-size nature of the window can result in severing words, sentences, or paragraphs impeding comprehension and disrupting the flow of information and understanding.
- Semantic chunking. This method divides the text into chunks based on semantic understanding. Division boundaries are focused on sentence subject and use significant computational algorithmically complex resources. However, it has the distinct advantage of maintaining semantic consistency within each chunk. It’s useful for text summarization, sentiment analysis, and document classification tasks.
Semantic chunking with Document Intelligence Layout model
Markdown is a structured and formatted markup language and a popular input for enabling semantic chunking in RAG (Retrieval-Augmented Generation). You can use the Markdown content from the Layout model to split documents based on paragraph boundaries, create specific chunks for tables, and fine-tune your chunking strategy to improve the quality of the generated responses.
Benefits of using the Layout model
- Simplified processing. You can parse different document types, such as digital and scanned PDFs, images, office files (docx, xlsx, pptx), and HTML, with just a single API call.
- Scalability and AI quality. The Layout model is highly scalable in Optical Character Recognition (OCR), table extraction, and document structure analysis. It supports 309 printed and 12 handwritten languages, further ensuring high-quality results driven by AI capabilities.
- Large language model (LLM) compatibility. The Layout model Markdown formatted output is LLM friendly and facilitates seamless integration into your workflows. You can turn any table in a document into Markdown format and avoid extensive effort parsing the documents for greater LLM understanding.